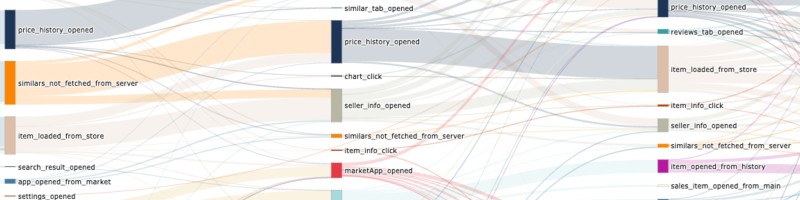
Давайте я расскажу, чем сейчас занимаюсь в Data Driven Lab (хантинга пост). TL;DR Нанимаем аналитиков с уклоном в математику/ML/python. Релоцируем в Белград. Моя команда занимается исследованиями пользовательского поведения по кликстриму (a.k.a. CJM). То есть на входе у нас всегда датасет с тремя колонками типа user_id, event, timestamp, а на выходе нужно сказать про этот кликстрим что-то полезное для бизнеса. Здесь и EDA (как вообще ведут себя пользователи, где узкие места в CJM, где теряем пользователей/деньги), и кластеризация (какие кластеры пользовательского поведения есть), и классификация (как предсказать появление таргетного события у пользователя), и построение моделей, описывающих поведение пользователей, и симуляции (что будет, если немного изменить CJM). Понятно, что для каждой из этих задач в мире дата саенса есть свои методы, но одна из основных проблем нашей предметной области заключается в том, что данные не так-то просто охватить взглядом и понять, что там вообще происходит. Поэтому нашей киллер-фичой является питоновская библиотека retentioneering, которая позволяет аналитикам по всякому крутить кликстрим в jupyter, визуализировать траектории пользователей (как на картинке к посту), ну и применять разные другие инструменты анализа кликстрима. Если вы хоть раз пытались строить подобные визуализации самостоятельно, как это делал в своё время я до прихода в DDL, то наверняка понимаете, насколько это всё геморно и одноразово, и какие удобства здесь можно было бы создать автоматическими инструментами. Помимо описанных удобств, добавочная ценность, которую мы создаём -- это возможность точного манипулирования кликстримом. Не секрет, что подготовка данных для анализа занимает 80% времени аналитика, и в этой трудоёмкой работе очень легко допустить незаметные, но серьёзные ошибки. Использование retentioneering позволяет их к минимуму. Так вот, библиотека занимает важную нишу: это инструмент для аналитиков, созданный аналитиками. Сейчас она имеет 90К инсталлов. В работе приходится применять различные приёмы, связанные с: - марковскими и немарковскими процессами (смотрим на частоты переходов от одного пользовательского действия к другому), - NLP (последовательности действий в цепочке пользователя чем-то похожи на последовательности слов в предложении), - симуляциями и методом Монте-Карло, - process mining, - специальными методами кластерного анализа (динамика кластеров, анализ кластеров). Команда у нас маленькая, поэтому кроме ресёрча, аналитики пишут сравнительно много кода, который контрибьютится в библиотеку. Понятно, что как и в любой небольшой команде, энтузиазм и профессионализм для нас имеют критичное значение, поэтому мы ищем заинтересованных, технически подкованных и наукоёмких специалистов. И да, мы релоцируем в Белград. Если вы заинтересовались, пишите мне или в телегу нашему руководителю @Zavolskov_Vladislav. У него же можно прочитать о нашей команде с другого ракурса https://lnkd.in/gfWZUAxx
Ariel Chernyy
1 г
Добрый день, звучит очень интересно. формально я не совсем тру data scientist, но в последние пару лет все больше концентрируюсь на этом направлении. Был бы рад пообщаться. или пройти тествовое задание )
Kirill Nikolenko
1 г
Здравствуйте, я data-engineer, опыт работы более 5 лет, в данный момент ищу работу с релокацией в Белград, возможно вас заинтересует мое резюме. Спасибо!
Actively looking for internship for Fall 2024 (Technical Project management, Business/System Analysis) | Graduate Student @City University of Seattle | Computer Science
1 гЗвучит прям очень круто и интересно, Вова 👍